
 Claude
Claude  Perplexity
Perplexity 
12 Best Data Quality Management Tools for 2025
Explore the top 12 data quality management tools of 2025. Our deep-dive review covers features, pricing, pros, and cons to help you find the perfect solution.
TL;DR: Explore the top 12 data quality management tools of 2025. Our deep-dive review covers features, pricing, pros, and cons to help you find the perfect solution.
In a business environment driven by data, quality is non-negotiable. Inaccurate, inconsistent, or incomplete data leads directly to flawed analytics, misguided business strategies, wasted marketing spend, and damaged customer relationships. For sales teams, it means low email deliverability and ineffective outreach. For developers, it results in integration failures and unreliable applications. The core problem is clear: without a systematic approach, data entropy is inevitable, quietly eroding the foundation of your operations.
This is where dedicated data quality management tools become essential. They are the frontline defense against data decay, providing the frameworks needed to cleanse, standardize, validate, and monitor your data assets continuously. Moving beyond simple validation, these platforms offer comprehensive solutions for profiling data to identify anomalies, establishing quality rules, and resolving issues before they impact downstream systems like your CRM or analytics platforms.
This guide cuts through the noise to provide a deep, practical analysis of the 12 best data quality management tools on the market. We’re not just listing features; we are providing an in-depth resource to help you make an informed decision. For each tool, you’ll find:
- Honest pros and cons based on real-world application.
- Specific use cases for roles like sales reps, marketers, and developers.
- Detailed feature analysis and implementation considerations.
- Transparent pricing information to align with your budget.
- Screenshots and direct links to see the platforms in action.
Our goal is straightforward: to equip you with the insights needed to select a tool that doesn’t just clean your data but actively enhances its strategic value for your entire organization.
1. Truelist
Best For: High-Volume Email List Validation & Deliverability
Truelist emerges as a standout choice among data quality management tools, specifically engineered to perfect a critical data asset: your email list. While many tools offer broad data cleansing capabilities, Truelist provides a focused, high-performance solution for ensuring pristine email data hygiene. Its core strength lies in its truly unlimited validation model, which dismantles the restrictive, credit-based systems common in the industry. This allows businesses, from agile startups to enterprise marketing teams, to clean their entire email database without worrying about per-email costs.
Founded by Grant Ammons, the former head of engineering at ConvertKit, Truelist is built on a foundation of deep email infrastructure expertise. The platform’s algorithms execute a multi-layered verification process in real-time. This includes syntax checks, domain and MX record verification, and direct SMTP handshakes to confirm mailbox existence without sending an actual email. This comprehensive approach is highly effective at identifying and isolating invalid, inactive, disposable, and dangerous spam-trap addresses.
Key Strengths and Use Cases
Truelist excels in scenarios where email deliverability is directly tied to revenue and reputation. For Sales Development Representatives (SDRs) engaging in cold outreach, it drastically reduces bounce rates that could lead to domain blacklisting. Email marketers can use it to re-engage dormant segments or clean newly acquired lists, boosting campaign ROI and sender scores.
Expert Insight: The platform’s unlimited model is a game-changer for businesses with massive, ever-changing lists. It encourages proactive data hygiene rather than reactive, cost-prohibitive cleanups, fundamentally improving long-term email marketing performance.
Implementation and Features
Getting started is straightforward. Users can upload a CSV file directly through the clean, intuitive interface or automate the entire process via its robust REST API and one-click integrations with tools like Zapier, Clay.com, and Mailchimp. This seamless connectivity makes Truelist a powerful, automated component of any data quality management stack.
- Truly Unlimited Validations: A simple, transparent monthly subscription eliminates overage fees and credit management.
- Advanced Verification: Detects a wide array of problematic emails, including catch-all, disposable, and role-based accounts.
- Seamless Integrations: Features a powerful REST API and native connections to essential marketing and sales platforms.
- User-Friendly Experience: A clean UI and efficient export options simplify list management for non-technical users.
- GDPR Compliance: Ensures data handling practices meet stringent privacy standards.
Pricing: Offers a transparent, flat-rate monthly subscription for unlimited validations. You can start with a free trial to test the service.
Pros:
- Eliminates unpredictable costs with a simple, all-inclusive subscription.
- Powerful, real-time algorithms provide highly accurate validation results.
- Easy-to-use interface and robust API for flexible implementation.
Cons:
- Highly specialized in email data, not a general-purpose data quality tool.
- Lacks extensive public case studies or third-party awards.
Learn more at Truelist
2. Informatica – Data Quality and Observability
Informatica’s Intelligent Data Management Cloud (IDMC) is a powerful, enterprise-grade platform offering robust data quality and observability functions. It excels in large-scale, multi-cloud environments where automated data profiling, cleansing, and standardization are critical. This platform is particularly suited for organizations in regulated industries like finance and healthcare that require auditable data quality controls and governance at every step of the data lifecycle.
What sets Informatica apart is its AI-powered CLAIRE engine, which automates the discovery of data quality rules and provides recommendations for cleansing and matching. This significantly reduces the manual effort required to maintain high data standards across complex data pipelines. For example, a financial institution can use Informatica to automatically validate customer data against global address directories and identify duplicate records across disparate systems, ensuring compliance with KYC (Know Your Customer) regulations.
Key Features and Analysis
The platform integrates data quality as a core component of its broader data management capabilities, which is a major advantage for large enterprises seeking a unified solution.
- AI-Powered Automation: Informatica uses its CLAIRE AI engine to automate profiling, rule generation, and anomaly detection. This helps data teams proactively monitor data pipelines and prevent bad data from propagating through systems.
- Prebuilt Rules and Accelerators: The platform comes with an extensive library of prebuilt rules for common data quality issues like cleansing, standardization, and matching, accelerating implementation.
- Integrated Data Enrichment: Services like address verification are built-in, allowing for real-time data enrichment directly within data processing workflows.
- Unified Governance: Because it is part of the IDMC, its data quality capabilities are tightly integrated with data cataloging and governance, providing a holistic view of data health and lineage.
Pricing and Implementation
Informatica uses a consumption-based pricing model, which can be more flexible than traditional license-based structures, but the costs are primarily geared toward enterprise budgets. Full pricing details require a direct sales consultation. Implementation is often complex and may require certified professionals or a dedicated internal team with specialized skills, especially when integrating across a large, hybrid technology stack.
| Feature | Details |
|---|---|
| Ideal Use Case | Large enterprises in regulated sectors needing scalable, governed data quality. |
| Pricing Model | Consumption-based (custom quote required) |
| Implementation Complexity | High, often requires specialized expertise. |
| Unique Selling Point | Fully integrated data management platform with AI-driven automation. |
Website: https://www.informatica.com/products/data-quality.html
3. Qlik (Talend) – Talend Data Quality
Talend Data Quality, now part of the Qlik Talend Cloud, is a powerful solution designed to bridge the gap between technical data engineers and business users. It provides an accessible, self-service environment for data profiling, cleansing, masking, and deduplication, making it an excellent choice for organizations aiming to democratize data quality responsibilities. The platform excels at empowering non-technical teams to proactively manage the health of their own data assets.
What sets Talend apart is its built-in Trust Score, an instant, at-a-glance metric that assesses data quality based on validity, popularity, and completeness. This feature allows a business analyst, for example, to quickly evaluate a marketing dataset before launching a new campaign, ensuring contact information is accurate and standardized without needing deep technical intervention. This focus on usability and immediate feedback makes it one of the more intuitive data quality management tools for cross-functional teams.
Key Features and Analysis
Talend’s strength lies in its balance of user-friendly interfaces with robust, machine-learning-driven backend processes, all integrated within the broader Qlik ecosystem.
- Self-Service Data Profiling: Offers visual data profiling with summary statistics, enabling business users to quickly identify quality issues like null values or format inconsistencies.
- ML-Powered Deduplication: Uses machine learning to identify and merge duplicate records, moving beyond simple rule-based matching for greater accuracy.
- Built-in Trust Score: Provides an easily understandable, automated score for any dataset, giving users immediate confidence in their data’s reliability.
- Data Masking and Governance: Includes features to mask personally identifiable information (PII), enabling secure, policy-based data sharing for analytics and development.
Pricing and Implementation
Like many enterprise-grade solutions, Qlik Talend’s pricing is not publicly available and requires a direct sales consultation to receive a custom quote. The platform is designed for enterprise environments, so pricing reflects that scale. Implementation can be complex if integrating the full Qlik Talend Cloud suite, but the self-service nature of the Data Quality component can simplify adoption for specific use cases. Advanced features often rely on the broader platform’s capabilities.
| Feature | Details |
|---|---|
| Ideal Use Case | Organizations seeking a self-service tool for business and data teams. |
| Pricing Model | Custom quote required (enterprise-focused) |
| Implementation Complexity | Moderate to High, depending on the scope of integration. |
| Unique Selling Point | The intuitive Data Trust Score and strong user experience for non-technical users. |
Website: https://www.qlik.com/us/products/data-quality-governance
4. Collibra – Data Quality & Observability
Collibra’s Data Intelligence Cloud integrates data quality and observability as a core pillar of its broader governance framework. The platform excels at connecting data quality metrics directly to business context, making it a top choice for organizations prioritizing a governance-first approach. It is designed for businesses that need to not only fix data issues but also understand their impact on business processes and data products through lineage and catalog integration.
What sets Collibra apart is its ability to embed data quality within the fabric of data governance. The platform uses machine learning to automatically generate data quality rules based on discovered patterns and provides predictive, adaptive monitoring. For example, a retail company can use Collibra to automatically profile sales data, detect anomalies like sudden shifts in pricing formats, and immediately trace the impact of this bad data upstream to its source and downstream to sales reports, all within a single, unified interface.
Key Features and Analysis
Collibra’s strength lies in making data quality a shared responsibility, with workflows that route issues to the correct data owners for resolution, ensuring accountability.
- Automated and Adaptive Rules: The platform uses machine learning to auto-discover data patterns and suggests quality rules. It continuously monitors data and adapts its own quality thresholds over time.
- Integrated Issue Management: When a data quality rule fails, Collibra can automatically create an issue and assign it to the relevant data steward through integrated workflows, streamlining remediation.
- Unified Governance Context: Data quality scores are not siloed. They are displayed directly within the data catalog alongside metadata, lineage, and business glossary terms, providing a complete picture of data health.
- Impact Analysis: Its deep integration with data lineage allows users to perform impact analysis, quickly identifying which downstream applications and reports are affected by a data quality problem.
Pricing and Implementation
Collibra’s pricing is not publicly available and is tailored to enterprise needs, requiring a direct sales consultation. The total cost of ownership can be significant, reflecting its position as a comprehensive data intelligence platform. Implementation is typically a major project, requiring careful planning and often the assistance of implementation partners to integrate it deeply within an organization’s data ecosystem.
| Feature | Details |
|---|---|
| Ideal Use Case | Governance-driven enterprises needing to link data quality to business context. |
| Pricing Model | Custom (quote required) |
| Implementation Complexity | High, often requires professional services or certified partners. |
| Unique Selling Point | Deep integration of data quality with a market-leading data governance platform. |
Website: https://www.collibra.com/products/data-quality-and-observability
5. Ataccama – ONE Data Quality
Ataccama ONE is a unified data management and governance platform that embeds AI-native data quality at its core. It is designed for organizations seeking to automate data quality checks, manage reference and master data, and enforce governance policies within a single, cohesive environment. The platform excels at proactively identifying and resolving data issues before they impact business intelligence or operational systems, making it a strong choice for data-driven enterprises.
What distinguishes Ataccama is its focus on self-service and AI-powered automation, which significantly lowers the barrier to entry for business users. Its “data quality firewall” concept allows teams to set up automated checks that prevent bad data from entering critical systems. For instance, a retail company could use Ataccama to automatically profile new product data, detect missing attributes like price or SKU, and quarantine the records for review, ensuring data integrity across its e-commerce platform.
Key Features and Analysis
Ataccama’s strength lies in its all-in-one approach, which reduces the complexity of integrating separate tools for data quality, master data management (MDM), and governance. This makes it one of the more comprehensive data quality management tools available.
- AI-Assisted Rule Authoring: The platform suggests data quality rules based on automated data profiling and analysis, allowing users to create complex validation logic with minimal manual effort.
- Proactive Anomaly Detection: Ataccama continuously monitors data streams and uses machine learning to detect anomalies and data drift, providing early warnings to data stewards.
- Integrated MDM and Governance: Data quality is not a standalone function but is tightly coupled with master data management, reference data management, and data cataloging for a holistic view of data assets.
- Data Quality Firewall: This feature enables automated, preventative data quality checks that can be applied to data ingestion points, stopping poor-quality data before it pollutes downstream systems.
Pricing and Implementation
Ataccama’s pricing is tailored to enterprise needs and requires a custom quote based on the specific modules and scale of deployment. While powerful, the platform has a learning curve, particularly when leveraging its full suite of advanced features like MDM. Implementation is often best handled with support from Ataccama’s professional services or a knowledgeable internal team.
| Feature | Details |
|---|---|
| Ideal Use Case | Mid-to-large enterprises needing a unified DQ, MDM, and governance platform. |
| Pricing Model | Custom quote required |
| Implementation Complexity | Moderate to High, depending on the scope of modules implemented. |
| Unique Selling Point | AI-powered data quality firewall integrated within a single governance platform. |
Website: https://www.ataccama.com/platform/data-quality/
6. Ataccama via AWS Marketplace
For organizations deeply embedded in the Amazon Web Services ecosystem, procuring Ataccama’s powerful data quality tools through the AWS Marketplace offers a streamlined and financially efficient path to implementation. This approach simplifies the often-complex procurement process by integrating the software purchase directly into existing AWS billing, allowing companies to leverage their committed AWS spend. It’s an ideal solution for tech-forward teams who want to deploy a leading data quality management tool without navigating separate vendor contracts and payment systems.
What makes this channel stand out is its transparent, tier-based pricing structure and the ability to spin up Ataccama’s capabilities natively within an established cloud environment. For example, a data engineering team can quickly deploy Ataccama ONE to profile, cleanse, and monitor data flowing into an Amazon S3 data lake or Redshift data warehouse. This integration accelerates time-to-value and ensures that data quality management is a native component of their cloud data architecture, rather than a bolted-on solution.
Key Features and Analysis
The primary benefit of this option is procurement and deployment simplicity for existing AWS customers, wrapping Ataccama’s robust platform into a familiar operational framework.
- Simplified Procurement: Enables purchasing through AWS Marketplace, consolidating billing and leveraging existing enterprise agreements with AWS.
- Transparent Pricing Tiers: Published 12-month contract tiers (Essential, Professional, Enterprise) for US-based customers provide clear cost benchmarks, although final pricing is vendor-negotiated.
- AWS Spend Alignment: Allows businesses to count Ataccama software costs toward their AWS Enterprise Discount Program (EDP) commitments, optimizing cloud budgets.
- Native Cloud Integration: Facilitates faster deployment and integration of Ataccama’s data quality suite within an organization’s existing AWS infrastructure.
Pricing and Implementation
While the AWS Marketplace lists tiered pricing to provide a baseline, the final costs are determined through a private offer from the vendor. Buyers must also account for the underlying AWS infrastructure costs required to run the platform. Implementation is streamlined from a procurement perspective, but deploying and configuring Ataccama itself still requires data management expertise, especially when integrating with complex data sources within a VPC.
| Feature | Details |
|---|---|
| Ideal Use Case | AWS-centric organizations seeking simplified procurement and budget alignment. |
| Pricing Model | Tier-based (custom quote via private offer) |
| Implementation Complexity | Medium; simplified procurement but still requires platform expertise. |
| Unique Selling Point | Streamlined acquisition and billing integration within the AWS ecosystem. |
Website: https://aws.amazon.com/marketplace/pp/prodview-2gw4c63hau4uo
7. IBM – InfoSphere QualityStage
IBM InfoSphere QualityStage is a mature, enterprise-focused data quality solution designed for complex data landscapes. It excels at deep data profiling, robust standardization, and sophisticated record matching, making it a powerful choice for organizations needing to cleanse and consolidate customer or party data from disparate legacy and modern systems. This tool is often leveraged by large corporations in sectors like banking and insurance that have accumulated data over decades and require a powerful engine to create a single source of truth.
What sets QualityStage apart is its probabilistic matching engine and extensive library of prebuilt rules, which are finely tuned for handling complex data variations. For instance, a global bank could use it to identify and merge duplicate customer profiles that exist with slight name variations, different address formats, and incomplete data points across its retail banking, wealth management, and loan systems. This capability is crucial for master data management (MDM) initiatives and regulatory compliance.
Key Features and Analysis
As one of the more established data quality management tools, QualityStage offers deep, battle-tested capabilities that are tightly integrated with the broader IBM data fabric ecosystem.
- Deep Data Profiling: The tool provides comprehensive profiling with over 200 built-in rules and 250+ data classes to automatically analyze and classify data structure, content, and quality.
- Advanced Standardization and Matching: Its core strength lies in cleansing, standardizing, and deduplicating records using advanced algorithms, which is ideal for creating a master customer view.
- Flexible Deployment: QualityStage is available on-premises or in the cloud (as part of IBM Cloud Pak for Data), offering flexibility for different enterprise IT strategies.
- Integrated Governance: It works seamlessly with IBM’s data governance stack, providing integrated reporting and using machine learning for term assignment to enforce data policies.
Pricing and Implementation
IBM’s pricing is geared toward large enterprises and requires direct engagement with their sales team for a custom quote. The implementation process can be complex, often demanding specialized IBM skills or certified partners to integrate the solution effectively within an existing technology infrastructure. The tool’s power comes with a steeper learning curve compared to more modern, self-service platforms.
| Feature | Details |
|---|---|
| Ideal Use Case | Large enterprises with complex data integration and MDM initiatives. |
| Pricing Model | Enterprise (custom quote required) |
| Implementation Complexity | High, requires specialized skills and often professional services. |
| Unique Selling Point | Advanced probabilistic matching and standardization for customer data. |
Website: https://www.ibm.com/products/infosphere-qualitystage
8. Precisely – Trillium Quality
Precisely’s Trillium Quality is a specialized data quality management tool that shines in complex data environments, particularly those focused on customer and product data. It is engineered for both scalable batch processing and real-time data services, making it a strong choice for enterprises that need to embed data cleansing and validation directly into their operational applications, such as CRMs or ERPs. The platform excels at standardizing, matching, and enriching global data sets.
What sets Trillium Quality apart is its long-standing expertise in global address verification and identity resolution. For a multinational company managing customer data across different countries, Trillium can validate addresses against local postal standards while simultaneously identifying and merging duplicate customer profiles. This ensures a single, accurate view of the customer, which is critical for marketing, compliance, and customer service initiatives. Its open APIs and flexible deployment options (cloud, on-premises, or hybrid) allow it to integrate smoothly into diverse IT ecosystems.
Key Features and Analysis
The platform is designed to act as a centralized hub for data quality services, ensuring consistency across an organization’s various applications and systems.
- Global Data Integrity: Offers robust verification rules for global address, name, and contact data, supporting numerous countries and local postal standards.
- Centralized Quality Services: Enables businesses to create and manage data quality rules centrally and deploy them as services accessible via open APIs across multiple applications.
- Flexible Deployment: Supports on-premises, cloud, and hybrid deployments, providing adaptability for different infrastructure strategies.
- Strong Matching and Linking: Advanced algorithms for fuzzy matching and survivorship help create a single customer view by accurately identifying and linking related records.
Pricing and Implementation
Precisely does not publicly disclose its pricing; interested organizations must contact their sales team for a custom quote. Implementation complexity can vary depending on the scale and number of system integrations. While its open APIs facilitate integration, achieving a fully centralized data quality service hub often requires dedicated IT resources and a clear data governance strategy. For a complete data management solution, it may need to be paired with other governance or cataloging tools.
| Feature | Details |
|---|---|
| Ideal Use Case | Enterprises needing to embed high-accuracy customer data validation into core business applications. |
| Pricing Model | Custom quote required. |
| Implementation Complexity | Moderate to high, depending on integration scope. |
| Unique Selling Point | Best-in-class global address and identity resolution capabilities. |
Website: https://www.precisely.com/product/precisely-trillium/trillium-quality
9. Oracle – Enterprise Data Quality (EDQ)
Oracle Enterprise Data Quality (EDQ) is a comprehensive data quality management tool designed to integrate seamlessly within the broader Oracle ecosystem. It provides a robust suite of capabilities for profiling, cleansing, matching, and standardizing data, making it an ideal choice for organizations already invested in Oracle technologies for Master Data Management (MDM), business intelligence, and data integration. The platform excels at managing complex party and product data across the enterprise.
What makes Oracle EDQ stand out is its deep integration with Oracle’s technology stack and its availability on the Oracle Cloud Infrastructure (OCI) Marketplace. This allows for simplified provisioning and deployment on familiar application servers like Tomcat or WebLogic. For example, a company using Oracle Siebel CRM can leverage EDQ to parse, standardize, and match customer records in real-time, ensuring that only high-quality, de-duplicated data enters their core business systems.
Key Features and Analysis
Oracle EDQ’s strength lies in its ability to operate as a centralized data quality hub for other Oracle applications, providing consistent rule application and governance.
- Comprehensive Data Processing: The platform offers powerful tools for parsing unstructured data, profiling datasets to identify anomalies, standardizing values, and matching records to find duplicates.
- Integrated Address Verification: An optional Loqate Address Verification Server can be integrated to provide global address cleansing and validation, which is critical for customer data management.
- Case Management: Includes a built-in case management feature that allows data stewards to manually review and resolve complex data quality issues flagged by automated processes.
- OCI Marketplace Deployment: Oracle provides pre-built images on the OCI Marketplace, significantly simplifying the deployment and configuration process for cloud-based environments.
Pricing and Implementation
Oracle’s pricing for EDQ is typically part of a larger enterprise license agreement, and specific details require direct consultation with their sales team. Implementation is most straightforward for organizations already using Oracle products, as the integration points are well-defined. However, it can be complex and may require specialized knowledge of the Oracle stack, particularly when connecting to non-Oracle systems.
| Feature | Details |
|---|---|
| Ideal Use Case | Organizations deeply invested in the Oracle ecosystem needing integrated data quality. |
| Pricing Model | Enterprise licensing (custom quote required) |
| Implementation Complexity | Moderate to High, best suited for teams with Oracle expertise. |
| Unique Selling Point | Seamless integration with Oracle applications and simplified OCI deployment. |
Website: https://www.oracle.com/middleware/technologies/enterprise-data-quality.html
10. SAP – Information Steward
SAP Information Steward is a comprehensive data quality management tool designed primarily for enterprises heavily invested in the SAP ecosystem. It provides robust capabilities for data profiling, monitoring, and metadata management, enabling organizations to gain clear insights into the health of their data assets. Its core strength lies in establishing a governed data stewardship process, complete with scorecards and dashboards that make data quality metrics transparent and actionable across business units.
What makes SAP Information Steward particularly effective in its intended environment is its deep integration with SAP systems like S/4HANA and Business Warehouse. This allows for seamless metadata management and end-to-end data lineage tracking from source to report. For example, a manufacturing firm can use Information Steward to profile supplier data within its SAP ERP, create cleansing rules to standardize addresses, and monitor the data quality score over time, ensuring that procurement analytics are based on reliable information.
Key Features and Analysis
The tool is built to support a formal data governance framework, making it a strong choice for organizations looking to operationalize their data policies.
- Data Profiling and Scorecards: It offers detailed data profiling to uncover inconsistencies and provides intuitive scorecards and dashboards to monitor quality trends against defined business rules.
- Metadata Management: The platform centralizes metadata management, helping users understand data definitions, relationships, and business context across different systems.
- Data Lineage Tracking: Users can visualize the complete data journey, from its origin to its consumption in reports, which is crucial for impact analysis and regulatory compliance.
- Clear Stewardship Workflows: It facilitates collaboration between business and IT by defining clear roles and responsibilities for data stewards to manage and remediate data quality issues.
Pricing and Implementation
SAP Information Steward is typically licensed as an on-premises solution, with pricing dependent on the scale of deployment. Full cost details are available through direct consultation with SAP sales. While powerful, its on-premises focus means implementation can be complex, especially when integrating with non-SAP sources. Moving to a more cloud-native model often requires adopting the broader SAP Business Technology Platform (BTP).
| Feature | Details |
|---|---|
| Ideal Use Case | SAP-centric enterprises requiring strong governance and data stewardship. |
| Pricing Model | Enterprise license-based (custom quote required). |
| Implementation Complexity | High, especially for on-premises and hybrid environments. |
| Unique Selling Point | Deep integration with the SAP ecosystem for seamless lineage and governance. |
Website: https://www.sap.com/products/technology-platform/data-profiling-steward.support.html
11. Soda – Data Quality Platform
Soda is a developer-focused, cloud-native data quality platform designed for modern data stacks. It offers a powerful combination of pipeline testing, observability, and alerting, making it a strong choice for teams that want to embed data quality checks directly into their data pipelines using a “checks-as-code” methodology. The platform is ideal for data engineers and analytics engineers who prefer to define, manage, and automate data quality monitoring programmatically.
What sets Soda apart is its approachable, code-based framework using SodaCL (Soda Checks Language) and its Python library. This allows teams to quickly define sophisticated data quality tests and integrate them seamlessly with tools like dbt, Airflow, Snowflake, and BigQuery. For instance, an analytics team can write a SodaCL check to ensure that a critical sales table never contains null values in the order_id column and automate this validation to run every time their dbt model is updated, preventing bad data from reaching their BI dashboards.
Key Features and Analysis
Soda’s strength lies in its integration into the engineering workflow, treating data quality as a core component of the development lifecycle, not an afterthought.
- Checks-as-Code: SodaCL and the Python SDK allow data teams to version-control, collaborate on, and automate data quality checks just like they do with application code.
- Deep Integration: Native integrations with major data warehouses (Snowflake, BigQuery), data processing tools (dbt, Spark), and orchestrators (Airflow) enable checks at every stage of the pipeline.
- Automated Monitoring: The platform can automatically scan data to detect anomalies, schema changes, and other data quality issues without manual rule configuration.
- Observability and Alerting: Provides a centralized view of data health over time with proactive alerting via Slack, email, and other channels to quickly notify teams of failures.
Pricing and Implementation
Soda offers a transparent, usage-based pricing model that is particularly attractive for teams wanting to start small and scale. A generous free tier is available, with paid plans offering unlimited users and advanced features. Implementation is straightforward for technical teams, as it involves connecting data sources and defining checks in code, leading to a very fast time-to-value compared to more monolithic data quality management tools.
| Feature | Details |
|---|---|
| Ideal Use Case | Data engineering and analytics teams wanting to automate quality testing in CI/CD pipelines. |
| Pricing Model | Usage-based with a free tier; paid plans are based on datasets monitored. |
| Implementation Complexity | Low for technical users; primarily involves code and configuration. |
| Unique Selling Point | Developer-first “checks-as-code” approach for data quality monitoring. |
Website: https://www.soda.io/pricing
12. Google Cloud – Dataplex Auto Data Quality
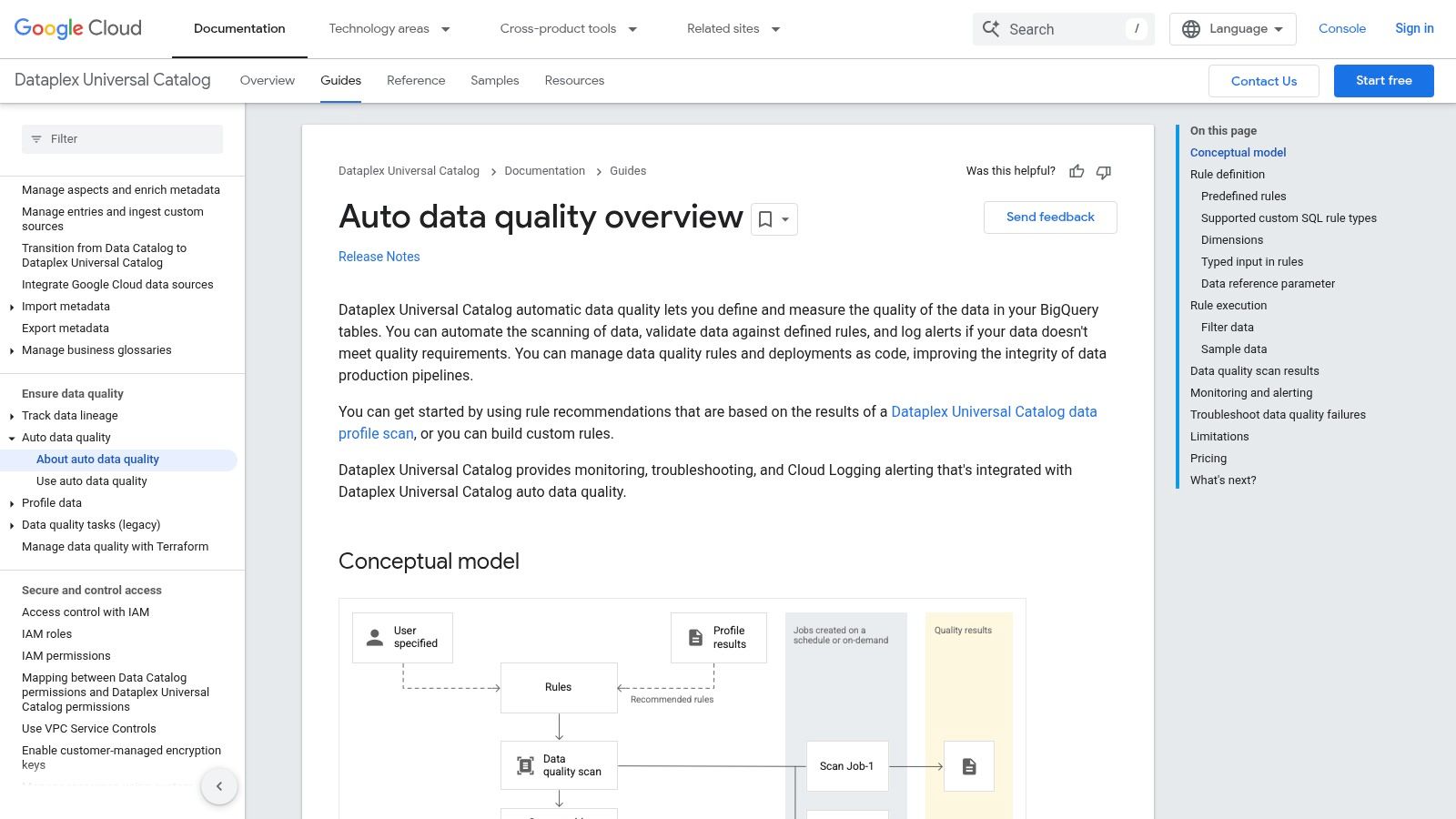
For organizations heavily invested in the Google Cloud Platform (GCP) ecosystem, Dataplex Auto Data Quality offers a seamless, native solution for monitoring data health. It is integrated directly into Dataplex and focuses on automating data quality checks for BigQuery tables and files in Cloud Storage. This tool is ideal for data engineering teams who need to build trust in their GCP-based data assets without introducing a separate, third-party platform.
What makes Dataplex stand out is its simplicity and tight integration. It automates data profiling to recommend quality rules, such as nullness checks or range validations, which can be accepted with a single click. For instance, a data engineer can configure a job to scan a BigQuery table daily, receive alerts in Cloud Logging if customer IDs are unexpectedly null, and visualize quality score trends over time in Looker Studio, all within the familiar GCP environment.
Key Features and Analysis
Dataplex positions itself as a streamlined, “good enough” data quality tool for GCP-centric organizations, prioritizing ease of use over the extensive feature sets of enterprise-grade platforms.
- Automated Rule Recommendations: The service profiles your data to suggest relevant data quality rules, significantly reducing the manual effort required to define checks.
- Cost-Effective Scanning: It supports incremental scans (checking only new data) and data sampling, giving users fine-grained control over processing costs.
- Native GCP Alerting and Reporting: Failures trigger alerts in Cloud Logging and can be configured to fire notifications via Pub/Sub or other GCP services. Results are exported to BigQuery for easy reporting in Looker Studio.
- Declarative YAML Configuration: Data quality scans are defined as code using YAML files, enabling integration with CI/CD pipelines for a DataOps approach.
Pricing and Implementation
Pricing is based on Google Cloud’s consumption model, primarily tied to the Dataform processing units (DPUs) used to run the scans. This pay-as-you-go model is cost-effective for smaller workloads but requires monitoring to manage expenses at scale. Implementation is straightforward for anyone familiar with GCP, requiring minimal infrastructure setup as it’s a fully managed service. However, its functionality is currently limited to data sources within BigQuery and Cloud Storage.
| Feature | Details |
|---|---|
| Ideal Use Case | GCP-native organizations needing automated quality checks for BigQuery. |
| Pricing Model | Consumption-based (per DPU-hour) |
| Implementation Complexity | Low, for teams already on Google Cloud. |
| Unique Selling Point | Seamless, serverless integration within the Google Cloud ecosystem. |
Website: https://cloud.google.com/dataplex/docs/auto-data-quality-overview
Data Quality Management Tools Comparison: Top 12 Features
| Platform | Core Features / Validation | User Experience / Quality ★★★★☆ | Value Proposition 💰 | Target Audience 👥 | Unique Selling Points ✨ | Price Points 💰 |
|---|---|---|---|---|---|---|
| 🏆 Truelist | Real-time email format, domain & mailbox checks | User-friendly UI, robust exports | Unlimited validations, simple monthly | SDRs, marketers, developers | One-click integrations, GDPR-compliant, expert-led | Transparent monthly subscription |
| Informatica | Automated profiling, cleansing, address verify | Enterprise-grade, mature support | Consumption-based cloud pricing | Large enterprises, regulated sectors | AI-powered rules, multi-cloud readiness | Enterprise pricing, inquiry needed |
| Qlik (Talend) | Profiling, ML deduplication, masking, Trust Score | Smooth self-service UI | Strong governance integration | Business users, data engineers | ML-enabled features, self-service balance | Enterprise pricing on request |
| Collibra | Auto-discovery, adaptive thresholds, governance | Integrated quality & catalog | Centralized data intelligence cloud | Enterprises needing governance | Quality linked to lineage and governance | Pricing not public |
| Ataccama ONE | AI-native rules, anomaly detection, MDM/RDM | Automated, AI-assisted workflows | Unified platform reduces overhead | Mid to large enterprises | Natural language rule generation | Enterprise-level pricing |
| Ataccama via AWS Marketplace | AWS billing, 12-month tiers | Simplified AWS procurement | Transparent US pricing benchmarks | AWS-centric organizations | Native AWS integration, private offers | Transparent contract tiers |
| IBM InfoSphere QualityStage | Extensive profiling, matching, ML-assisted | Mature matching & standardization | Flexible deployment options | Enterprises needing deep data quality | 200+ rules, broad IBM ecosystem | Enterprise sales process |
| Precisely Trillium Quality | Data cleansing, address verification | Proven large-scale customer data use | Strong global address capabilities | CRM, customer data managers | Open APIs, postal standards supported | Contact sales |
| Oracle Enterprise Data Quality | Parsing, standardization, matching, Loqate addr | Seamless Oracle ecosystem integration | Robust party data quality | Oracle ecosystem users | OCI Marketplace deployment | Oracle licensing required |
| SAP Information Steward | Profiling, scorecards, lineage, governance | Clear stewardship workflows | SAP-centric governance solution | SAP-centric enterprises | Detailed dashboards and metadata management | On-premises focused |
| Soda Data Quality Platform | Pipeline testing, observability, alerts | Fast time-to-value, transparent pricing | Usage-based cost model, free tier | Data teams needing quick deployment | Checks-as-code, broad integrations | Transparent, usage-based |
| Google Cloud Dataplex Auto DQ | Automated profiling, rule recs, cloud alerts | Native GCP integration, fine cost control | GCP-native, minimal setup | BigQuery & Cloud Storage users | Incremental scans, Looker reporting | Included in GCP billing |
From Clean Data to Confident Decisions
Navigating the landscape of data quality management tools can feel overwhelming, but the journey from messy, unreliable data to a state of strategic clarity is a transformative one. As we’ve explored, the market offers a diverse array of solutions, from enterprise-grade powerhouses like Informatica and IBM InfoSphere QualityStage to modern, developer-centric platforms like Soda and Google Cloud Dataplex. Each tool carves out its own niche, proving that there is no single “best” solution, only the one that aligns perfectly with your organization’s unique needs, technical infrastructure, and strategic goals.
The central takeaway is clear: data quality is not a one-time cleanup project but an ongoing discipline. Tools like Collibra and Ataccama ONE champion this by integrating data governance and observability directly into their quality frameworks, promoting a proactive culture of data stewardship. Meanwhile, legacy giants like Oracle EDQ and SAP Information Steward offer deep, proven capabilities for organizations already heavily invested in their respective ecosystems. The choice you make will fundamentally shape how your business leverages its most valuable asset.
Synthesizing Your Selection Criteria
Selecting the right tool requires a clear-eyed assessment of your specific circumstances. Don’t be swayed by an exhaustive feature list if you only need a fraction of the functionality. Instead, anchor your decision-making process around these critical questions:
- Scale and Complexity: Are you a small business managing a few critical datasets or a global enterprise with a sprawling data lakehouse? Your data volume and the complexity of your pipelines will immediately narrow the field.
- Primary Use Case: Is your main pain point operational data integrity, regulatory compliance, business intelligence accuracy, or customer data validation for outreach? A specialized tool like Truelist is ideal for sales and marketing teams, whereas a platform like Qlik (Talend) is built for complex ETL/ELT transformations.
- Technical Ecosystem: How will the tool integrate with your existing cloud provider (AWS, Google Cloud), data warehouses, and BI platforms? Seamless integration prevents the creation of new data silos and reduces implementation friction.
- User Personas: Who will be the primary users? Business analysts will thrive with the user-friendly interfaces of tools like Precisely Trillium, while data engineers may prefer the code-first, YAML-based approach of a platform like Soda.
Beyond the Tool: Implementing a Culture of Quality
Remember, even the most advanced data quality management tools are only as effective as the processes and people that support them. Successful implementation goes beyond technical configuration. It involves establishing clear data ownership, defining universal quality standards, and creating feedback loops that empower teams to identify and resolve issues at their source.
Your chosen tool should act as a catalyst for this cultural shift. It provides the visibility to diagnose problems, the automation to enforce rules, and the metrics to demonstrate the tangible business value of clean data. This value manifests in more accurate forecasts, higher marketing ROI, improved customer satisfaction, and ultimately, more confident, data-driven decisions across every department. The investment you make today in data quality is a direct investment in the future resilience and intelligence of your entire organization.
Stop validating once and hoping for the best. Truelist’s recurring validation automatically re-checks your lists on a schedule — catching new bounces, dead mailboxes, and risky addresses before they damage your sender reputation. No credits, no per-email charges.